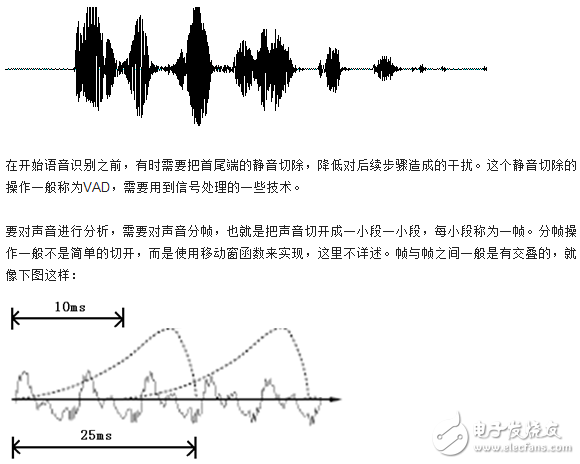
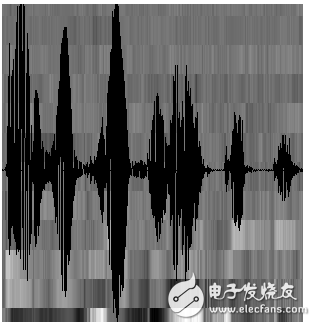
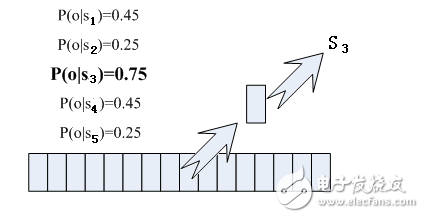
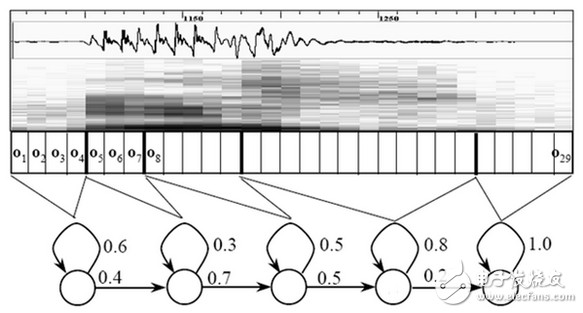
Today, with the rapid development of artificial intelligence, speech recognition has become the standard for many devices. Speech recognition has begun to attract more and more people's attention. Foreign manufacturers such as Microsoft, Apple, Google, nuance, domestic science and technology companies such as Xunfei and Spitz, etc. Both are developing new strategies and algorithms for speech recognition, and it seems that the natural interaction between humans and speech is approaching. We all hope that as smart and advanced voice assistants as in "Iron Man", when communicating with the robot, let it understand what you are saying. Speech recognition technology has turned this once-human dream into reality. Speech recognition is like a "machine's auditory system." This technology allows machines to recognize and understand and convert speech signals into corresponding text or commands. Speech recognition technology, also known as AutomaTIc Speech RecogniTIon (ASR), whose goal is to convert vocabulary content in human speech into computer-readable input, such as keystrokes, binary codes, or character sequences. Unlike speaker recognition and speaker confirmation, the latter attempts to recognize or confirm the speaker who made the speech rather than the vocabulary content contained therein. Below we will explain in detail the principles of speech recognition technology. Speech recognition is based on speech as the research object. Through speech signal processing and pattern recognition, the machine automatically recognizes and understands human spoken language. Speech recognition technology is a high technology that allows machines to transform speech signals into corresponding text or commands through recognition and understanding. Speech recognition is a wide-ranging interdisciplinary subject. It has a very close relationship with acoustics, phonetics, linguistics, information theory, pattern recognition theory, and neurobiology. Speech recognition technology is gradually becoming a key technology in computer information processing technology. The application of speech technology has become a competitive emerging high-tech industry. The speech recognition system is essentially a pattern recognition system, including three basic units such as feature extraction, pattern matching, and reference pattern library. Its basic structure is shown in the following figure: The unknown voice is converted into an electrical signal by a microphone and then added to the input of the recognition system. First, it is preprocessed, and then a voice model is established according to the characteristics of human voice, the input voice signal is analyzed, and the required features are extracted. Create the template required for speech recognition. In the recognition process, the computer should compare the characteristics of the voice template stored in the computer with the input voice signal according to the model of voice recognition, and according to a certain search and matching strategy, find a series of optimal matches with the input voice template. Then according to the definition of this template, the identification result of the computer can be given by looking up the table. Obviously, this optimal result is directly related to the choice of features, the quality of the speech model, and the accuracy of the template. The construction process of speech recognition system includes two parts: training and recognition. Training is usually done offline. Signal processing and knowledge mining are performed on the pre-collected massive speech and language databases to obtain the "acoustic model" and "language model" required by the speech recognition system; the recognition process is usually done online. Automatically recognize the user's real-time voice. The recognition process can usually be divided into "front-end" and "back-end" modules: the main function of the "front-end" module is to perform endpoint detection (removing excess silence and non-speaking sounds), noise reduction, feature extraction, etc .; The function of the "end" module is to use the trained "acoustic model" and "language model" to perform statistical pattern recognition (also known as "decoding") on the feature vectors of the user's speech to obtain the text information it contains. In addition, the back-end module also There is an "adaptive" feedback module, which can self-learn the user's voice, so as to "correct" the "acoustic model" and "speech model", and further improve the accuracy of recognition. Speech recognition is a branch of pattern recognition, and it belongs to the field of signal processing science. At the same time, it has a very close relationship with the disciplines of phonetics, linguistics, mathematical statistics and neurobiology. The purpose of speech recognition is to allow the machine to "understand" human spoken language, which includes two meanings: one is to understand the word-by-word non-conversion into written language; the second is to respond to the requirements or queries contained in the spoken language Understand and respond correctly without being constrained by the correct conversion of all words. There are three basic principles of automatic speech recognition technology: first, the language information in the speech signal is encoded according to the time-varying pattern of the short-term amplitude spectrum; secondly, the speech is readable, that is, its acoustic signal can be transmitted without considering the speaker. In the case of information content, it is represented by dozens of distinctive and discrete symbols; the third voice interaction is a cognitive process, and therefore cannot be separated from the grammar, semantics, and pragmatic structure of the language. Acoustic model The model of the speech recognition system usually consists of two parts: an acoustic model and a language model, which respectively correspond to the calculation of the probability of speech to syllable and the calculation of the probability of syllable to word. Acoustic modeling; language model search for The search in continuous speech recognition is to find a word model sequence to describe the input speech signal, thereby obtaining the word decoding sequence. The search is based on scoring the acoustic model and language model in the formula. In actual use, it is often necessary to add a high weight to the language model based on experience, and set a long word penalty score. System implementation The requirement for the speech recognition system to select the recognition primitive is that it has an accurate definition, can obtain enough data for training, and is general. English is usually modeled with context-sensitive phonemes, and Chinese's collaborative pronunciation is not as serious as English, and syllable modeling can be used. The size of the training data required by the system is related to the complexity of the model. The design of the model is too complicated to exceed the ability of the training data provided, which will cause a sharp decline in performance. Dictation machine: Large vocabulary, non-specific person, continuous speech recognition system is usually called dictation machine. Its architecture is the HMM topology based on the aforementioned acoustic model and language model. During training, the model parameters are obtained by using a forward and backward algorithm for each primitive. When identifying, the primitives are concatenated into words, and a silent model is added between words and a language model is introduced as the transfer probability between words to form a cyclic structure. Algorithm to decode. In view of the characteristics of easy segmentation of Chinese, segmentation and decoding of each segment is a simplified method to improve efficiency. Dialogue system: The system used to realize man-machine spoken dialogue is called dialogue system. Limited by the current technology, the dialogue system is often oriented to a narrow field, limited vocabulary system, its subject matter includes travel query, booking, database search, etc. The front end is a speech recognizer. The generated N-best candidate or word candidate grid is analyzed by the grammar analyzer to obtain semantic information, and then the response information is determined by the dialog manager and output by the speech synthesizer. Because current systems often have limited vocabulary, keywords can also be extracted to obtain semantic information. First, we know that sound is actually a wave. Common mp3 and other formats are all compressed formats, which must be converted to uncompressed pure waveform files for processing, such as Windows PCM files, also known as wav files. In addition to a file header stored in the wav file, it is a point of the sound waveform. The figure below is an example of a waveform. In the figure, the length of each frame is 25 ms, and there is an overlap of 25-10 = 15 ms between every two frames. We call it frame division with frame length 25ms and frame shift 10ms. After framing, the voice becomes many small segments. But the waveform has almost no description ability in the time domain, so the waveform must be transformed. A common transformation method is to extract the MFCC features, and according to the physiological characteristics of the human ear, transform each frame of the waveform into a multi-dimensional vector, which can be simply understood that this vector contains the content information of this frame of speech. This process is called acoustic feature extraction. In practical applications, there are many details in this step, and the acoustic characteristics are not limited to the MFCC, which is not described here. So far, the sound has become a matrix of 12 rows (assuming 12-dimensional acoustic features) and N columns, called the observation sequence, where N is the total number of frames. The observation sequence is shown in the following figure. In the figure, each frame is represented by a 12-dimensional vector, and the color depth of the color block indicates the size of the vector value. Next, we will introduce how to turn this matrix into text. First, two concepts are introduced: Phonemes: The pronunciation of words consists of phonemes. For English, a commonly used phoneme set is a set of 39 phonemes at Carnegie Mellon University, see The CMU Pronouncing DicTIonary. Chinese generally uses all initials and finals directly as phoneme sets. In addition, Chinese recognition is divided into tones and non-tones, which will not be described in detail. Status: This is understood to be a more detailed phonetic unit than a phoneme. Usually a phoneme is divided into 3 states. How does speech recognition work? Actually it is not mysterious at all, it is nothing more than: The first step is to identify the frame as a state (difficulty). In the second step, the states are combined into phonemes. The third step is to combine phonemes into words. As shown below: In the figure, each small vertical bar represents a frame, several frames of speech correspond to a state, every three states are combined into a phoneme, and several phonemes are combined into a word. In other words, as long as you know which state each frame of speech corresponds to, the result of speech recognition will come out. Which state does each frame phoneme correspond to? There is an easy way to think about which state corresponds to which state a frame has the highest probability. For example, in the following schematic diagram, the conditional probability of this frame in state S3 is the largest, so guess this frame belongs to state S3. Where do you read the probabilities used? There is something called an "acoustic model", which contains a lot of parameters, and through these parameters, you can know the probability of the frame and the state. The method of obtaining this large number of parameters is called "training", which requires the use of a huge amount of voice data, and the training method is cumbersome, and I will not talk about it here. But there is a problem with this: every frame will get a status number, and finally the whole voice will get a bunch of messy status numbers. The status numbers between two adjacent frames are basically different. Suppose there are 1000 frames of speech, and each frame corresponds to a state, and every 3 states are combined into a phoneme, then it will probably be combined into 300 phonemes, but there is not so many phonemes at all in this speech. If you do so, the obtained status numbers may not be combined into phonemes at all. In fact, it should be reasonable that the states of adjacent frames are mostly the same because each frame is very short. The common method to solve this problem is to use Hidden Markov Model (HMM). This thing sounds very deep, but it is actually very simple to use: The first step is to build a state network. The second step is to find the path that best matches the sound from the state network. In this way, the results are limited to the pre-set network, which avoids the problem just mentioned, and of course brings a limitation. For example, the network you set includes only "today is sunny" and "it is raining". The state path of the sentence, no matter what is said, the result of the recognition must be one of the two sentences. What if you want to recognize arbitrary text? Make the network large enough to include any text path. But the larger the network, the harder it is to achieve better recognition accuracy. Therefore, according to the needs of the actual task, the size and structure of the network should be reasonably selected. To build a state network is to expand from a word-level network to a phoneme network, and then to a state network. The speech recognition process is actually to search for an optimal path in the state network, and the probability that the voice corresponds to this path is the largest. This is called "decoding". The path search algorithm is a dynamic programming pruning algorithm, called Viterbi algorithm, used to find the global optimal path. The cumulative probability mentioned here consists of three parts, namely: Observation probability: the probability of each frame and each state Probability of transition: the probability that each state transitions to itself or to the next state Language Probability: Probability based on language statistics Among them, the first two probabilities are obtained from the acoustic model, and the last one is obtained from the language model. Language models are trained using a large amount of text, and the statistical rules of a language can be used to help improve recognition accuracy. The language model is very important. If the language model is not used, when the state network is large, the recognition result is basically a mess. This basically completes the speech recognition process, which is the principle of speech recognition technology. Generally speaking, the working process of a complete speech recognition system is divided into 7 steps: Basic block diagram of sound recognition system The basic principle structure of the speech recognition system is shown in the figure. There are three principles of speech recognition: ①The language information in the speech signal is encoded according to the time variation of the amplitude spectrum; ② Because the speech is readable, that is to say, the acoustic signal can be used without regard to the content of the information conveyed by the speaker Under the premise, it is represented by multiple distinctive and discrete symbols; ③ The interaction of speech is a cognitive process, so it must not be separated from aspects such as grammar, semantics, and terminology. Pre-processing includes sampling the speech signal, overcoming the aliasing filter, removing part of the noise caused by the differences in individual pronunciations and the environment, and also considering the selection of basic units of speech recognition and endpoint detection. Repetitive training is to make the speaker repeat the speech many times before recognition, remove redundant information from the original speech signal samples, retain key information, and then organize the data according to certain rules to form a pattern library. Furthermore, pattern matching, which is the core part of the entire speech recognition system, is based on certain rules and calculating the similarity between input features and inventory patterns, and then judges the meaning of the input speech. Front-end processing, the original speech signal is processed first, and then feature extraction is performed to eliminate the impact of noise and pronunciation differences of different speakers, so that the processed signal can more completely reflect the essential feature extraction of speech, eliminating noise and different The influence of the speaker's pronunciation difference makes the processed signal more completely reflect the essential characteristics of speech. The idea of ​​automatic speech recognition has been put on the agenda long before the computer was invented. Early vocoders can be regarded as the prototype of speech recognition and synthesis. The "Radio Rex" toy dog ​​produced in the 1920s may be the earliest voice recognizer. When the dog's name is called, it can pop up from the base. The earliest computer-based speech recognition system is the Audrey speech recognition system developed by AT & T Bell Laboratories, which can recognize 10 English digits. Its recognition method is to track the formants in speech. The system got a 98% accuracy rate. By the end of the 1950s, Denes of the College of London (Colledge of London) had added grammatical probabilities to speech recognition. In the 1960s, artificial neural networks were introduced to speech recognition. The two major breakthroughs in this era are Linear PredicTIve Coding (LPC) and Dynamic Time Warp technology. The most significant breakthrough in speech recognition technology is the application of Hidden Markov Model. Relevant mathematical reasoning was proposed from Baum. After research by Labiner et al., Kai-Fu Lee of Carnegie Mellon University finally realized Sphinx, the first large-vocabulary speech recognition system based on hidden Markov model. Strictly speaking, the speech recognition technology has not been separated from the HMM framework since then. A huge breakthrough in laboratory speech recognition research was born in the late 1980s: People finally broke through the three major obstacles of large vocabulary, continuous speech, and non-specific people in the laboratory. For the first time, these three features were integrated into one In the system, the Sphinx system of Carnegie Mellon University (CarnegieMellonUniversity) is more typical. It is the first high-performance non-person-specific, large vocabulary continuous speech recognition system. During this period, speech recognition research went further, and its salient feature is the successful application of HMM model and artificial neural network (ANN) in speech recognition. The wide application of the HMM model should be attributed to the efforts of scientists such as Rabiner of the AT & TBell laboratory. They engineered the original difficult HMM pure mathematical model to understand and recognize more researchers, so that the statistical method has become the mainstream of speech recognition technology. .
Products Description :
Products Features :
Power Inverter,Modified Sine Inverter,Modified Square Wave Inverter,Modified Or Pure Sine Wave Inverter zhejiang ttn electric co.,ltd , https://www.ttnpower.com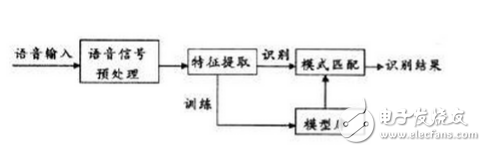

â‘ Analyze and process the voice signal to remove redundant information.
â‘¡ Extract key information affecting speech recognition and feature information expressing language meaning.
â‘¢ Close to feature information, use the smallest unit to identify words.
④ Identify words according to their respective grammars in different languages ​​and in order.
⑤ Use the context before and after as an auxiliary identification condition, which is conducive to analysis and identification.
â‘¥ According to the semantic analysis, divide the key information into paragraphs, take out the recognized words and connect them, and adjust the sentence structure according to the meaning of the sentence.
⑦Combining semantics, carefully analyzing the interrelationship of contexts, and appropriately revising the sentences currently being processed. 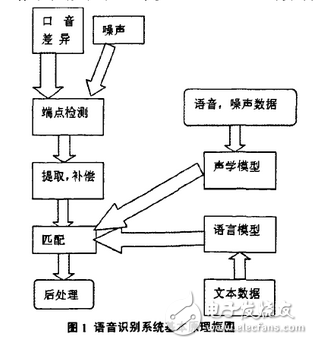
In the early 1990s, many well-known large companies such as IBM, Apple, AT & T and NTT invested heavily in the practical research of speech recognition systems. Speech recognition technology has a good evaluation mechanism, that is, the accuracy of recognition, and this indicator has been continuously improved in laboratory research in the mid and late 1990s. More representative systems include: ViaVoice from IBM and NaturallySpeaking from DragonSystem, NuanceVoicePlatform from Nuance, Microsoft's Whisper, Sun's VoiceTone, etc.
TTN Power inverter offer superior quality true sine wave output, it is designed to operate popular power tools and sensitive loads. Connect pure sine wave inverter with battery terninals, then you can get AC power for your appliances, the AC output identical to, and in some cases better than the power supplied by your utility.
- Input & output fully insolated.
- High Surge: high surge current capability starts difficult loads such as TVs,camps,motors and other inductive loads.
- Grounding Protection: there is terminal in front panel, you can grouding the inverter.
- Soft start: smooth start-up of the appliances.
- Pure sine wave output waveform: clean power for sensitive loads.
- AC output identical to, and in some cases better than the power supplied by your utility.
- Cooling fan works automatically when inverter becomes too hot, it turns off automatically when the temperature is reduced.
- Low total harmonic distortion: below 3%.
- Two LED indicators on the front panel showthe working and failure state.




