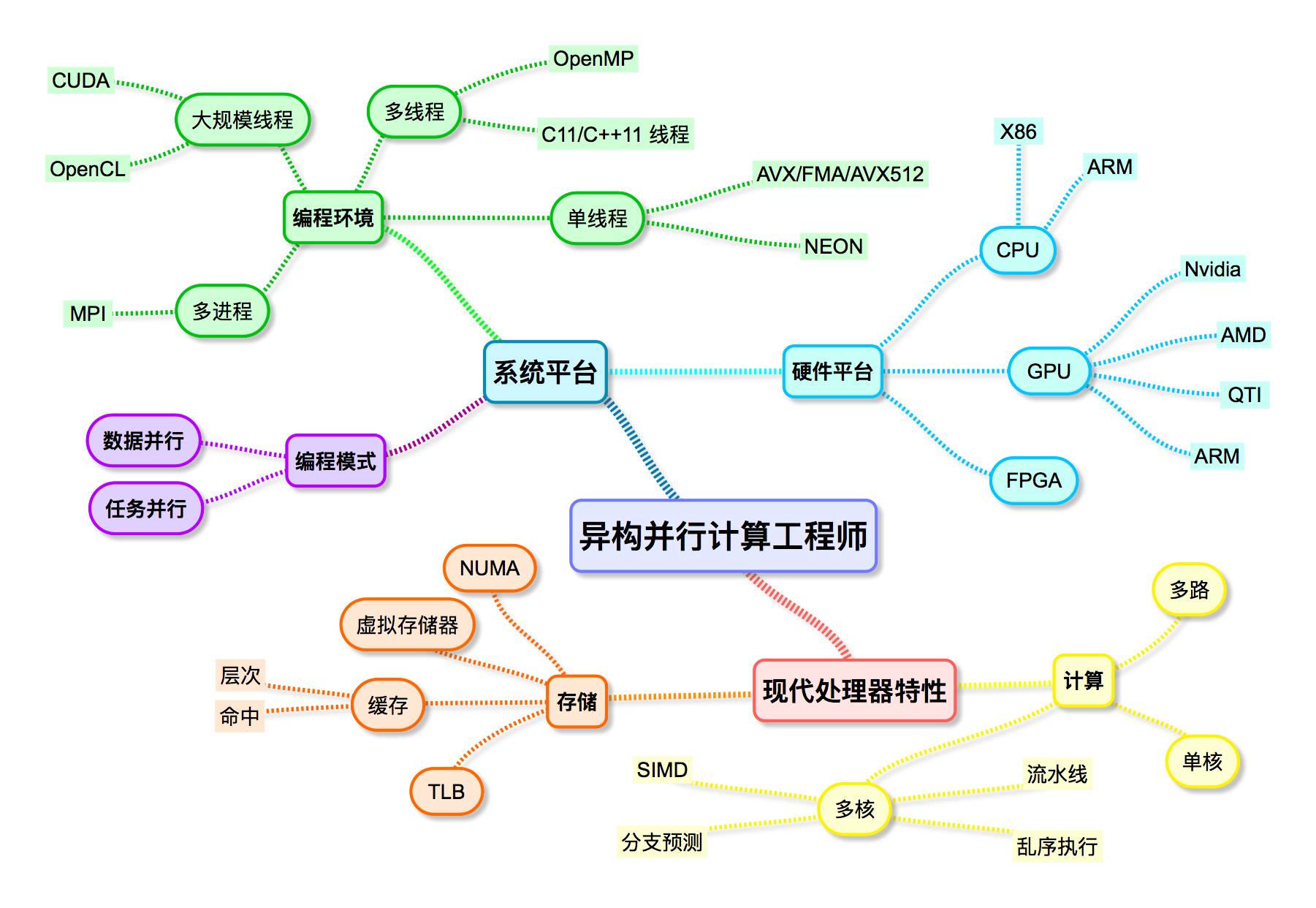
With the popularity of deep learning (artificial intelligence), heterogeneous parallel computing has received more and more attention from the industry. From the beginning, talking about deep learning must talk about GPU, and when talking about deep learning, we must talk about computing power. Computational power is not only related to the specific hardware, but also to the level of the person who can use the hardware capabilities (ie, the heterogeneous parallel computing power). A simple metaphor is that the computing power of the two chips is 10T and 20T respectively. Someone has a heterogeneous parallel computing power of 0.8. He got a chip with a computing power of 10T, and a person with a heterogeneous parallel computing power of 0.4 got it. The chip with a computing power of 20T, and in fact the final result may not be the same. People with strong heterogeneous parallel computing capabilities can better utilize the capabilities of the hardware, and the goal of this paper is to tell the reader what knowledge to learn as a heterogeneous parallel computing engineer. Heterogeneous parallel computing is a concept proposed by the author. It is essentially a combination of heterogeneous computing and parallel computing. On the one hand, heterogeneous parallel computing engineers need to master the knowledge of heterogeneous computing at the same time, and also need to master parallel computing. Knowledge; on the other hand, to better develop and enrich heterogeneous computing and parallel computing. The heterogeneous parallel computing further enhances the systemicity and relevance of knowledge, enabling every heterogeneous parallel computing engineer to get the job he wants and get a worthy salary. For the day-to-day work of a heterogeneous parallel computing engineer, his work involves a wide range of aspects, including hardware, software, systems, and communication. It is a position with very high requirements for hard power and soft power. The difficulty of heterogeneous parallel computing is very high, and the market demand for this position has been increasing. I hope that readers can join me in the ranks of heterogeneous parallel computing and contribute to the promotion of heterogeneous parallel computing in China. Heterogeneous Parallel Computing Engineer Skill Tree To be a good heterogeneous parallel computing engineer requires a lot of knowledge and skills, these skills can be divided into two areas: a processor system, how the processor executes specific instructions; In terms of the system platform, this can be divided into multiple sub-themes, including hardware features, software programming-related platforms and infrastructure. Readers can learn more about the skills and knowledge that heterogeneous parallel computing engineers need to master from Figure 1. Figure 1 Heterogeneous Parallel Computing Engineer Skill Tree Detailed development of heterogeneous parallel computing engineers Everyone and every technology field is constantly growing. Usually, the company's position is divided into primary, intermediate, senior, director, etc., which is divided according to contribution, ability and responsibility. It is not suitable for representing technology. . In order to better help readers to learn knowledge, this paper analyzes from the perspective of skill system, so it does not correspond to the job requirements of each company. It also means that readers cannot simply match the skills of this article with the job level of each company. In order to help readers better understand, this article will use the software first software introduction. From the point of view of the hardware knowledge that is most relevant to heterogeneous parallel engineers, namely processor characteristics. Modern processor characteristics From the start of the system to the termination, the processor executes the instructions in the memory one by one. From the perspective of the user, it seems that the next instruction is executed after the execution of the previous instruction. It is a complete serial. process. In fact, modern processors utilize instruction-level parallelism. At the same time, multiple instructions are executed at the same time, and the order in which the processor executes instructions does not need to be exactly the same as that given by the assembly code. The compiler and processor only need to To ensure that the final result is consistent, such processors are called "out-of-order execution processors." A processor that executes one instruction at a time in strict order, only the processor that starts executing the next instruction after the previous one is executed is called an "in-order processor." Even if the processor is executed sequentially, the compiler can perform similar optimizations on the source code to improve program performance. For a particular pipeline, modern out-of-order execution processors only guarantee that the instruction execution phase can be out of order, while other phases are usually sequential. At present, mainstream CPUs and GPUs, and even DSPs, are basically out-of-order execution processors on the server side or on the mobile side. Most of today's processors are variants of the Harvard architecture. The fundamental feature is that instructions and data are stored separately during program execution. Programmers can usually ignore instruction storage. In fact, heterogeneous parallel computing is more concerned with: computation and data. access. Calculation and memory The processor E5-2680v3, which is being used by the author, has a clock speed of 2.6 GHz and supports the FMA instruction set. Its single-core single-precision floating-point calculation capability is 2.6*2*8*2=83.2 GFlops; and single-channel memory The bandwidth is approximately 20GB/s. The processing speed of mainstream processors is much faster than the read and write speed of memory. In order to reduce the delay in accessing data, modern mainstream processors mainly adopt two methods: The local nature of accessing data using a program: a series of small and fast caches are used to store the data being accessed and will be accessed. If the data is accessed multiple times and the data can be cached, it can be approximated by the memory. Get a speed that approximates the cache; Utilize the parallelism of the program: When one control flow is blocked due to high-latency operation, another control flow is executed, which can improve the utilization of the processor core and ensure that the processor core is always busy. Simply put, the former method is to save frequently accessed data in a low-latency cache to reduce latency when accessing data, and improve performance by providing data to the processor faster, mainly for current mainstream CPU adoption. The latter method tries to ensure that the computing unit is always busy, and improves the throughput of the program by improving the utilization of the hardware. This method is currently mainly used by mainstream GPUs. There are no natural barriers to these two approaches. Modern processors (whether CPU or GPU) use these two methods, but the difference is only which method is used. Instruction level parallelism Modern processors have many features related to code performance optimization. This section focuses on the following sections: Instruction-level parallel technology: mainly pipeline, multi-issue, VLIW, out-of-order execution, branch prediction, superscalar and other technologies; Vectorization: mainly SIMT and SIMD technologies; Software developers who understand these features of modern multicore vector processors can write code that is more efficient than the average developer. Multicore Multicore refers to a CPU module that contains multiple cores. Each core is an independent computing entity that can execute threads. Modern processors are multi-core processors and are optimized for multi-core usage scenarios. Each core of the multicore has a separate level 1 cache, shared or independent level 2 cache, and some machines have independent or shared level 3 / level 4 caches, all core shared memory DRAM. Usually the first level cache is exclusive to one core of the multi-core processor, and the last level cache (Last Level Cache, LLC) is shared by all cores of the multi-core processor, and the middle layers of most multi-core processors are also exclusive. of. For example, Intel Core i7 processor has 4-8 cores, some versions support Hyper-Threading, each core has independent primary data cache and instruction cache, unified L2 cache, and all cores share a unified L3 cache. . Due to shared LLC, when a multi-threaded or multi-process program is running on a multi-core processor, the average LLC cache occupied by each process or thread is smaller than when using a single thread, which makes certain LLC or memory-limited applications available. Scalability doesn't look so good. Since each core of a multi-core processor has a separate level and sometimes a separate level 2 cache, you can take advantage of these core-exclusive caches when using multi-threaded/multi-process programs. This is super linear acceleration. One of the reasons for the performance gains on multicore processors that exceed the number of cores). Multiple ways with NUMA Hardware manufacturers also package multiple multicore chips together, called multipaths, and access memory in a way that is between sharing and exclusive. Due to the lack of buffering between multiple channels, the communication cost is usually not lower than that of DRAM. Some multicores also encapsulate the memory controller into multiple cores and connect directly to the memory to provide higher memory bandwidth. There are also two concepts related to memory access on the road: UMA (Uniform Memory Access) and NUMA (Non-Uniform Memory Access). UMA means that the delay of any one of the multiple core access memory is the same. NUMA is opposite to UMA, and the core access is close to it (meaning that the number of intermediate nodes to pass through when accessing) is less. If the locality of the program is very good, you should turn on NUMA support for the hardware. Hardware platform The capabilities of heterogeneous parallel computing personnel ultimately need to be proven by programs running on hardware, which means that the knowledge of hardware by heterogeneous parallel computing programmers is directly and directly related to their capabilities. At present, the main types of processors that come into contact with you are: X86, ARM, GPU, FPGA, etc., and the difference between them is very large. X86 The X86 is a collective term for a series of CPU processors produced by Intel/AMD and related manufacturers, and is also seen by everyone. X86 is widely used on desktops, servers, and the cloud. SSE is a vector instruction supported by the X86 vector multi-core processor. It has 16 vector registers of 128 bits (16 bytes) in length. The processor can simultaneously operate 16 bytes in the vector register, thus having higher bandwidth and Calculate performance. AVX extends the SSE vector length to 256 bits (32 bytes) and supports floating point multiply and add. Now Intel has increased the vector length to 512 bits. Due to the explicit SIMD programming model, the use of SSE/AVX is difficult and the scope is limited. It is a painful thing to use it for programming. The MIC is Intel's many-core architecture. It has about 60 X86 cores, each of which includes vector and scalar units. The vector unit consists of 32 vector registers of 512 bits (64 bytes) in length, supporting 16 32-bit or 8 64-bit simultaneous operations. The core of the current MIC is sequential, so its performance optimization method is very different from the X86 processor core based on out-of-order execution. In order to reduce the complexity of using SIMD instructions, Intel hopes that its compiler optimization capabilities, in fact, Intel's compiler vectorization capabilities are very good, but usually hand-written vector code performance will be better. When programming on the MIC, the software developer's work portion is converted from explicit vector instructions to rewritten C code and adds compiled guidance statements to allow the compiler to produce better vector instructions. In addition, modern 64-bit X86 CPUs use SSE/AVX instructions to perform scalar floating-point operations. ARM Currently, high-end smartphones and tablets use multiple ARM cores and multiple GPU cores. In the era of artificial intelligence, applications running on mobile devices have increasing computing performance requirements. Due to battery capacity and power consumption, it is impossible for mobile terminals to use desktop or server high-performance processors, so they have performance optimization. High demand. The high-performance ARM processors currently on the market are mainly 32-bit A7/A9/A15, which has 64-bit A53/A57/A72. The ARM A15 MP is a multi-core vector processor with 4 cores, each with 64KB of L1 cache and 4 cores with up to 2MB of L2 cache. The vector instruction set supported by ARM 32 is called NEON. NEON has 16 vector registers of 128 bits in length (these registers start with q, or 32 32-bit registers, starting with d), and can operate 16 bytes of the vector register at the same time, so you can use vector instructions. Higher performance and bandwidth. The ARM A72 MP is a multi-core vector processor with up to 4 cores, each with 32KB of primary data cache and 4 cores with up to 4MB of unified L2 cache. The vector instruction set supported by ARM 64 is called asimd. The instruction function is basically compatible with neon, but the register and the stacking rules are obviously different, which means that the assembly code written by neon is not compatible with asimd. GPU GPGPU is a general-purpose computing task that uses a GPU that handles graphics tasks to perform processing (unrelated to graphics processing) that was originally handled by the CPU. Thanks to the powerful parallel processing capabilities and programmable pipeline of modern GPUs, they can handle non-graphical data. Especially in the face of single instruction stream multiple data stream (SIMD), and the amount of data processing is much larger than the data scheduling and transmission needs, GPGPU greatly exceeds the traditional CPU application performance. The GPU is designed to render a large number of pixels. It does not care about the processing time of a pixel, but rather the number of pixels that can be processed per unit time, so bandwidth is more important than latency. Considering that the large number of pixels being rendered is usually not related, the GPU uses a large number of transistors for parallel computing, so it has a higher computing power than the CPU on the same number of transistors. CPU and GPU hardware architecture design ideas are very different, so its programming methods are very different, many developers using CUDA have the opportunity to revisit the painful experience of learning assembly language. The programming ability of the GPU is not strong enough, so you must have a detailed understanding of the GPU features, know which ones can be done, and which ones can't be done. It will not happen that there is a function that cannot be realized or the performance is poor after the project is developed. Case. Since the GPU uses a larger proportion of transistors for calculation, the ratio used for caching is relatively smaller than that of the CPU, so applications that generally satisfy the CPU requirements and do not meet the GPU requirements are not suitable for the GPU. Since the GPU hides the memory access delay through the parallelism of a large number of threads, some applications with very poor data locality can get good benefits on the GPU. Other applications with low computational memory ratios are difficult to achieve very high performance gains on the GPU, but this does not mean that the GPU implementation will be worse than the CPU implementation. CPU+GPU heterogeneous computing requires data to be transferred between the GPU and the CPU, and this bandwidth is smaller than the memory access bandwidth, so a solution that requires a large amount of frequent data interaction between the GPU and the CPU may not be suitable. Implemented on the GPU. FPGA FPGA is an abbreviation of field programmable gate array. With the popularity of artificial intelligence, FPGAs have received more and more attention from industry and academia. The main feature of FPGA is that it can be reconfigured by the user or the designer. The configuration of the FPGA can be performed in the hardware description language. The common hardware description languages ​​are VHDL and verilog. One of the things that is criticized with VHDL and Verilog programming is its programming speed. With the popularity of FPGAs, the programming speed is getting more and more attention. Each manufacturer has introduced their own OpenCL programming environment. Although OpenCL reduces the programming difficulty, its flexibility and performance are also greatly limited. Traditionally, FPGAs have been used for communication, and FPGAs are now also used for computing and hardware circuit design verification. The two mainstream FPGA vendors are Altera and Xilinx. Intel acquired Altera in 2014. It is estimated that in 2018, heterogeneous products of Intel X86+ FPGA will appear in the market. Programming environment This section will detail the current mainstream parallel programming environment, including common instruction-level parallel programming techniques, as well as thread-level parallel programming techniques and process-level techniques. Intel AVX/AVX512 Intrinsic SSE/AVX is an assembly instruction from Intel to exploit SIMD capabilities. Because assembly programming is too difficult, Intel later gave its built-in function version (intrinsic). The SSE/AVX instruction supports data parallelism. An instruction can operate on multiple data at the same time. The number of data to be operated at the same time is determined by the length of the vector register and the data type. For example, the SSE4 vector register (xmm) is 128 bits long, that is, 16 bytes. If you operate on float or int data, you can operate 4 at the same time. If you operate char data, you can operate 16 at the same time, and the AVX vector register (ymm) is 256 bits long, that is, 32 bytes. Although the SSE4/AVX instruction vector register is 128/256 bits long, it also supports smaller length vector operations. Under the 64-bit program, the number of SSE4/AVX vector registers is 16. SSE instructions require alignment, primarily to reduce the number of memory or cache operations. The SSE4 instruction requires 16-byte alignment, while the AVX instruction requires 32-byte alignment. SSE4 and previous SSE instructions do not support misaligned read and write operations. To simplify programming and extend the range of applications, AVX instructions support unaligned reads and writes. ARM NEON Intrinsic NEON is an extension of the SIMD instruction set on ARM processors. Due to the widespread use of ARM on the mobile side, the use of NEON is becoming more and more popular. NEON supports data parallelism. An instruction can operate on multiple data at the same time. The number of data to be operated at the same time is determined by the length of the vector register and the data type. ARMv7 has 16 128-bit vector registers named q0~q15. These 16 registers can be divided into 32 64-bit registers, named d0~d31. Among them, qn and d2n, d2n+1 are the same, so you should pay attention to avoid register coverage when writing code. OpenMP OpenMP is short for Open Multi-Processing and is a parallel environment based on shared memory. OpenMP supports C/C++/Fortran bindings and is also implemented as a library. Currently commonly used GCC, ICC and Visual Studio support OpenMP. The OpenMP API consists of the following parts: a set of compiler directives, a set of runtime functions, and some environment variables. OpenMP has been accepted by most computer hardware and software vendors as a de facto standard. OpenMP provides a high-level abstract description of parallel algorithms. The programmer inserts various pragma directives into the source code to indicate their intent. The compiler can then automatically parallelize the program and add synchronization to each other where necessary. Repel communication. When the choice tells the compiler to ignore these pragmas or the compiler does not support OpenMP, the program can degenerate into a serial program, and the code can still function normally, but it cannot use multithreading to speed up program execution. The high-level abstraction provided by OpenMP for parallel descriptions reduces the difficulty and complexity of parallel programming, so that programmers can devote more energy to the parallel algorithm itself rather than its implementation details. OpenMP is a good choice for multi-threaded programming based on data parallelism. At the same time, the use of OpenMP also provides greater flexibility to adapt to different parallel system configurations. Thread granularity and load balancing are some of the problems in traditional parallel programming, but in OpenMP, the OpenMP library takes over some of these tasks from the programmer. OpenMP is designed to be standard, simple, practical, easy to use, and portable. As a high-level abstraction, OpenMP is not suitable for situations where complex inter-thread synchronization, mutual exclusion, and precise control of threads are required. Another disadvantage of OpenMP is that it is not well used on non-shared memory systems (such as computer clusters). On such systems, MPI is more suitable. MPI MPI (Message Passing Interface) is a messaging programming environment. Messaging means that the user must exchange data between processors by explicitly sending and receiving messages. MPI defines a set of communication functions to send data from one MPI process to another MPI process. In message parallel programming, each control flow has its own independent address space. Different control flows cannot directly access each other's address space, and must be implemented through explicit message passing. This programming approach is the primary programming method used by massively parallel processors (MPPs) and clusters. Practice has shown that MPI is very scalable, whether it is on a small cluster of several nodes or on a large cluster with thousands of nodes. Because the message passing program design requires the user to decompose the problem well, organize the data exchange between different control flows, and the parallel computing has large granularity, which is especially suitable for large-scale scalable parallel algorithms. MPI is a process-based parallel environment. Processes have separate virtual address spaces and processor schedules, and are executed independently of each other. MPI is designed to support cluster systems connected via the network, and communication is realized through message passing. Message passing is the most basic feature of MPI. MPI is a representation of a standard or specification, not a specific implementation of it. MPI is the representative and de facto standard for distributed storage programming models. To date, all parallel computer manufacturers have provided support for MPI, and MPI can be implemented on different parallel computers for free on the Internet. A correct MPI program can be run on all parallel machines without modification. MPI only specifies the standard and does not give an implementation. At present, the main implementations are OpenMPI, Mvapich and MPICH. MPICH is relatively stable, while OpenMPI performs well. Mvapich is mainly designed for Infiniband. MPI is primarily used for parallel machines for distributed storage, including all major parallel computers. But MPI can also be used for shared storage parallel machines, such as multi-core microprocessors. Programming practice proves that MPI is very scalable, and its application range from small clusters of several machines to industrial clusters of tens of thousands of nodes for industrial applications. MPI has been implemented on Windows, on all major UNIX/Linux workstations, and on all major parallel machines. C or Fortran parallel programs that use MPI for messaging can run uninterrupted on workstations that use these operating systems, as well as on various parallel machines. OpenCL OpenCL (Open Computing Language), first designed by Apple and later maintained by Khronos Group, is an open standard for parallel programming of heterogeneous platforms and a programming framework. The Khronos Group is a non-profit technology organization that maintains multiple open industry standards and is widely supported by industry. OpenCL's design draws on CUDA's successful experience and supports multi-core CPUs, GPUs or other accelerators whenever possible. OpenCL not only supports data parallelism, but also supports task parallelism. At the same time, OpenCL has built-in support for multi-GPU parallelism. This makes OpenCL's application scope wider than CUDA, but currently OpenCL has more API parameters (because function overloading is not supported), so the function is relatively difficult to memorize. The areas covered by OpenCL include not only GPUs, but also a variety of other processor chips. Until now, the hardware supporting OpenCL has been mainly limited to CPU, GPU and FPGA. Currently, the OpenCL development environment mainly includes NVIDIA, AMD, ARM, Qualcomm, Altera and Intel. NVIDIA and AMD both provide OpenCL based on their own GPU. Implementation, while AMD and Intel provide OpenCL implementations based on their respective CPUs. At present, their implementation does not support products other than their own products. Due to the difference in hardware, portability may be affected in order to write code with excellent performance. OpenCL consists of two parts: one is language and API, and the other is architecture. In order for C programmers to learn OpenCL easily and simply, OpenCL only provides a very small extension to C99 to provide an API for controlling parallel computing devices and some ability to declare computing cores. Software developers can use OpenCL to develop parallel programs and get better portability on multiple devices. The goal of OpenCL is to write heterogeneous programs that can be compiled at various hardware conditions at once. Due to the different software and hardware environments of each platform, high performance and inter-platform compatibility will create conflicts. And OpenCL allows each platform to use the characteristics of its own hardware, which increases this contradiction. But if you don't allow each platform to use its own features, it will hinder hardware improvements. CUDA CUDA believes that the hardware that can be used for computing on the system consists of two parts: one is the CPU (called the host), the other is the GPU (called the device), the CPU controls/directs the GPU, and the GPU is just the coprocessor of the CPU. Currently CUDA only supports NVIDIA GPUs, and the CPU is responsible for the host-side programming environment. CUDA is an architecture and a language. As an architecture, it includes hardware architecture (G80, GT200, Fermi, Kepler), hardware CUDA computing power and how CUDA programs are mapped to GPU execution; as a language, CUDA provides the ability to utilize GPU computing power. All aspects of the function. CUDA's architecture includes its programming model, memory model, and execution model. The CUDA C language mainly explains how to define a computing kernel. The CUDA architecture is very different in hardware structure, programming method and CPU system. For the specific details of CUDA, readers can refer to CUDA related books. CUDA is designed based on the C/C++ syntax, so CUDA's syntax is easier to master for programmers familiar with the C-series language. In addition, CUDA only minimally extends ANSI C to achieve its key features: threads are organized in two levels, shared memory and barrier synchronization. Currently CUDA provides two APIs to meet the needs of different groups of people: runtime API and driver API. The runtime API is built on the driver API and the application can also use the driver API. The driver API provides additional control by demonstrating the concept of the lower layers. Initialization, context, and module management are implicit when using the runtime API, so the code is more concise. Generally, an application only needs to use one of the runtime API or the driver API, but it can be mixed at the same time. I recommend that readers prefer to use the runtime API. Programming mode Similar to serial programming, parallel programming also exhibits the characteristics of a pattern, which is an abstraction of a solution to a similar class of parallel algorithms. Similar to serial programming, parallel programming has different solutions for different application scenarios. Due to the special nature of parallelism, serial solutions cannot be directly ported to parallel environments, so it is necessary to rethink and design solutions. Parallel programming patterns are mostly naming data and tasks (procedural operations), and some are named programmatically. After decades of development, people have come up with a series of effective parallel models, and the application scenarios of these models are different. This section will briefly describe the features, applicable scenarios and scenarios of some common parallel modes. The specific description and implementation are described in detail later. It should be noted that from a different perspective, a parallel application may belong to multiple different parallel modes, and the essential reason is that there is overlap in these parallel modes. Since the patterns are not orthogonal, the approach that applies to one pattern may also apply to the other, and the reader needs to cite the opposite. Task parallel mode Task parallelism refers to each control flow computing one thing or calculating a sub-task of multiple parallel tasks, usually with a large granularity and little or no communication. Because it is similar to human thinking, task parallelism is more popular and easy to implement on the basis of the original serial code. Data parallel mode Data parallelism means that one instruction acts on multiple data at the same time. Then one or more data can be allocated to one control flow calculation, so that multiple control flows can be paralleled, which requires the data to be processed to have equal characteristics, ie There is almost no data that requires special handling. If the processing time for each data or each small data set is basically the same, then the data can be evenly divided; if the processing time is different, the load balancing problem should be considered. The usual practice is to make the number of data sets much larger than the number of control flows, and dynamically schedule to achieve load balancing. Data parallelism requires less control, so modern GPUs use this feature to significantly reduce the proportion of control units, while vacant units are used for calculations, which provides more native computing power on the same number of transistors. . Process-based, thread-based environments, and even instruction-level parallel environments are well-suited for data parallelism. If necessary, you can use these three programming environments at the same time, allocate threads in the process, and use the instruction level to process multiple data in parallel in the thread. This is called hybrid computing. Current status of heterogeneous parallel computing Prior to 2005, processors typically increased the frequency to improve computing performance, and because performance was predictable, there was a virtuous circle between hardware manufacturers, researchers, and software developers. Due to power constraints, processor frequencies cannot be increased, and hardware manufacturers are turning to vectorized or multi-core technologies. The rise of heterogeneous parallel computing represented by GPU computing, coupled with the artificial intelligence blessing, heterogeneous parallel computing from the academic world to the industry, has gained public recognition. Today almost all major processor hardware manufacturers are already supporting OpenCL, and heterogeneous parallel computing will be ubiquitous in the future. Today, both in technology and in the market, it has achieved considerable development. I can predict that in the next decade, heterogeneous parallel computing will inevitably further develop and generate value in more industries. Technological progress Due to the influence of the process, the integration of the chip will become more and more difficult. Now 14nm has been mass-produced, and the next 7nm will be very fast. As process technology reaches its limits, some manufacturers will lose their advantage over the leading generation of processes, and software companies will pay more attention to the value of heterogeneous parallel computing talent. And some hardware manufacturers will evolve into system vendors, no longer just provide pure hardware, and then the hardware and system software will be provided together, and the profits will be realized by transferring the cost of the software to the hardware. As the impact of heterogeneous parallel computing increases, vendors and organizations have developed a range of technologies, such as WebCL, OpenVX, and Vulkan. These technologies further enrich and expand the field of heterogeneous parallel computing, and promote heterogeneous parallel computing. Today, basically every hardware and system software company involves heterogeneous parallel computing more or less. Market demand With the rise of artificial intelligence, the market demand for people in the field of heterogeneous parallel computing has shifted from traditional scientific computing and image processing to the Internet and emerging enterprises. The current staff gap has been greatly increased. It can be found from 51job and Zhilian recruitment. Many recruitment information. Since there is still a clear cognitive gap between the capabilities of heterogeneous parallel computing developers and boss expectations and expenditures in the early days of the industry, coupled with the indirect reaction of heterogeneous parallel computing developers, There are games on multiple levels. For people in the field of heterogeneous parallel computing, this game is a bit unfair, because the professional characteristics require practitioners in the field of heterogeneous parallel computing to understand the algorithm implementation details better than the algorithm designer, and to understand the application of the algorithm more than the algorithm implementation personnel. The scene, plus the difficulty of programming and the need to spend more time. However, as the industry has just formed, the bosses are not aware of this. They just regard the heterogeneous parallel computing practitioners as ordinary developers, and contradictions arise. With the rise of artificial intelligence, the market's perception of heterogeneous parallel computing practitioners has become rational. More and more companies recognize that heterogeneous parallel computing is one of the core competencies of artificial intelligence enterprises. It is foreseeable that heterogeneous parallel computing engineers will become more and more popular in the near future.
RCA Cables can be used to connect a variety of audio and video devices, such as camcorders, to TVs or stereos to speakers. Most high-end camcorders have all three RCA jacks, so the signal entering or leaving the device goes through three separate channels-one video and two audio-resulting in a high-quality transfer. Lower-end camcorders usually have only one jack, called a stereo jack, which combines all three channels. This results in lower-quality transfers because the signal is compressed. In either case, RCA cables transmit analog, or non-digital, signals. Because of this, they cannot be plugged directly into a computer or other digital device. RCA cables connect amplifiers to all sorts of devices.
Ucoax OEM Cable Assembly RCA Cables
Quality of RCA Cables
Several factors affect the quality, price, and performance of RCA cables:
Materials: The connectors on RCA cables are often gold, silver, or copper. As you might expect, the gold connectors are the most expensive. They're also better than silver and copper connectors at preventing oxidation, but not as good at electrical conductivity. The silver connectors are best for electrical conductivity with the copper cables coming in a close second and the gold cables falling far behind. Other suitable materials are nickel, zinc, and tin.
Cable Length: Cable length has a negative effect on signal quality. Buy a cable that is only as long as you need it to make the connection for the best signal quality.
Shielding: A well-shielded cable delivers a better signal than one that lacks robust shielding.
The other end of the cable: If possible, match the material used in the other end of the cable to the material used in the connectors. Don't match tin with gold or silver with gold. Those combinations can cause problems because of an electrolytic reaction.
High Quality RCA Cables, Male to Male RCA Cable, RCA Cables for HDTV UCOAX , https://www.jsucoax.com